The Future of Decentralized Artificial Intelligence Operating Systems
“Nearly 70% of enterprises say decentralization will reshape their AI plans within five years.”
A shift that changes who controls data and computes.

📌 Highlights
-
✔What a decentralized AI operating system is and how it differs from centralized stacks.
-
✔Core architecture layers: infrastructure, data, model, lifecycle, and agents.
-
✔Practical use cases—edge, IoT, marketplaces—and the governance and security challenges to solve.
-
✔Decentralized operating systems run models and manage data across shared infrastructure to balance cost, latency, and compliance.
-
✔They matter now because organizations in the U.S. face control, cost, and risk trade-offs driven by large language models and generative services.
-
✔Adoption depends on both engineering (orchestration, schedulers, provenance) and governance (incentives, auditability).
-
✔Generative intelligence and on-demand content creation increase demand for coordinated compute, shared incentives, and verifiable model provenance.
-
✔Decentralization can improve resilience and local data controls, but it introduces new security and standardization needs.
Explore A Checklist For Assessing Decentralized Readiness — a practical tool to evaluate data controls, model lifecycle, orchestration, and governance across your teams.
This guide explains a new operating layer for artificial intelligence that runs models across shared infrastructure instead of relying on a single cloud provider. It defines the term in plain words, explains why decentralized approaches matter for U.S. organizations today, and highlights practical trade-offs in cost, resilience, and privacy.
Decentralized systems let organizations spread compute and data across many nodes—cloud, edge, and shared GPU pools so teams can lower costs, improve availability, and reduce concentration of control without moving all raw data to a single location.
The guide covers engineering and strategy: compute, networking, orchestration, data controls, ownership, governance, and compliance. It stays grounded in present capabilities, avoids science fiction hype, and focuses on measurable steps technical and business leaders can take now.
Readers will see concrete examples—large chat services, edge devices, IoT fleets, and enterprise analytics and learn how an operating system acts as the glue that coordinates models, enforces policies, and preserves provenance. The guide also outlines risks and the standards needed to manage them over time.
Why Decentralized AI Operating Systems Matter Now
As routine AI features evolve into powerful generative services, the need for coordinated, distributed compute and stronger data controls is immediate. Decentralized artificial intelligence operating systems make it practical to run models and learning pipelines across shared infrastructure so organizations can deliver low-latency, compliant services today without concentrating all data and compute in one provider.
From Everyday AI To Generative Breakthroughs
What started as embedded functionality recommendations, navigation, and spam filtering has expanded into systems that generate original content text, images, and other language outputs. Modern services increasingly rely on machine learning and deep learning models to create those outputs on demand, and that growth raises operational pressure at scale.
Training and serving these models consumes significant compute and power. Organizations managing peak loads for large chat services or multimodal apps often find that GPU sharing, request routing, and dynamic placement across nodes are no longer optional experiments but cost and performance imperatives. For example, splitting inference across edge nodes and shared GPU pools can reduce latency for end users while limiting raw data transfers.
What Does “Operating System” Mean Here
An OS in this context is a coordination layer that allocates compute, routes requests, manages identity and permissions, tracks provenance, and enforces policies across distributed nodes. It covers the full lifecycle training, tuning, evaluation, and updates so models and datasets behave like a single managed platform despite running across many machines and networks.
Open research ecosystems and shared tooling (model registries, federated frameworks, and interoperable packaging formats) accelerate adoption by improving reproducibility and lowering integration friction. For U.S. enterprises, this matters both technically and legally keeping data local by policy can help with privacy and regulatory compliance while enabling collective learning across partners.

| Aspect | Legacy | AI Decentralized OS |
|---|---|---|
| Scope | Single provider, siloed data | Shared compute, federated data control |
| Resource use | Dedicated clusters, fixed scale | Dynamic allocation, GPU, and edge sharing |
| Lifecycle coordination | Isolated training and serving | Coordinated training, tuning, and deployment |
Assess Your Latency And Cost Trade-Offs With Our Quick Calculator — a short tool to help teams evaluate whether to move inference to edge nodes, share GPU pools, or keep workloads centralized.
What Decentralized AI Operating Systems Are
A decentralized OS ties together scattered compute and storage so teams can run models across many sites. It is a set of software components and protocols that let independent machines coordinate compute, data access, and model execution as one logical platform for artificial intelligence workloads.

Definition And Scope
Scope splits across three axes: compute, data, and control. Compute defines where workloads run—cloud, edge, or shared GPU pools. Data covers where information lives and who may read it. Control covers rules, upgrades, and incentives that govern the network
Lifecycle Examples:
Security / compliance implication: Raw PII never leaves the origin site.
Security / compliance implication: Access controls and audit logs enforce who can update models.
Security / compliance implication: Signed artifacts and versioning prevent tampered rollouts.
Security / compliance implication: Data minimization reduces transfer risk.
How They Differ From Centralized Systems
Centralized setups usually mean one provider owns infrastructure, algorithms, and update cadence. A decentralized OS distributes ownership, reduces single points of failure, and can preserve local data while sharing models. In practice, this means more complex coordination (schedulers, policy routers, and trusted registries) but improved control over where data and computers live.
Learn More To Decentralized OS Readiness By Lifecycle Stage — a practical reference to evaluate compute placement, data controls, and rollout safety for your projects.
| Lifecycle Stage | Centralized | Decentralized |
|---|---|---|
| Training | Single data center | Federated or multi-site training |
| Tuning | Central teams update models | Local fine-tuning near data |
| Inference | Central API endpoints | Edge and shared inference pools |
Core Building Blocks and Architecture
At the core of a decentralized OS are layered components that decide where work runs, how data moves, and how models are versioned and maintained. Below are concise descriptions and practical takeaways for each layer to help architects and engineering leads evaluate trade-offs.
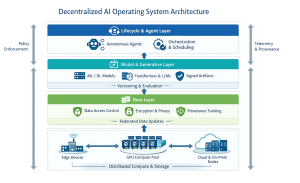
Distributed Infrastructure
Distributed infrastructure is a fleet of nodes (cloud, on‑prem, and edge devices) connected by resilient networks and managed by an orchestration layer. The scheduler places training or inference jobs based on capacity, policy, latency, and cost signals. It measures utilization, enforces quotas, and drives placement decisions, so workloads run where they best meet performance and compliance needs.
Data Layer
Data layer enforces identity, access control, and provenance so participants can prove which datasets or records contributed to a model and when. Privacy-aware pipelines combine minimization, encryption in transit and at rest, and policy routing so sensitive records remain local while aggregated updates or statistics move across nodes.
Model & Generative Layer
The model layer manages machine learning and deep learning artifacts—versioning, evaluation logs, rollback, and lifecycle metadata for neural networks at scale. Generative components (transformers and LLMs) live here, producing text and multimodal content. Training large foundation models often requires very large amounts of compute, which motivates pooled GPU sharing and on-demand inference markets.
Lifecycle And Agent Layers
The lifecycle layer covers training → tuning → evaluation → continual improvement, with standardized CI/CD-style workflows. The agent layer runs autonomous agents that orchestrate tools, call APIs, and coordinate multi-step processes across nodes.

Core Components: Infra, data, and model layers—must interoperate through policy-aware orchestration and signed artifacts.
| Component | Purpose | Operational need |
|---|---|---|
| Infrastructure | Run jobs on nodes | Scheduling, quotas, telemetry |
| Data layer | Control and provenance | Identity, encryption, policy routing |
| Model & generative | Manage models and LLMs | Versioning, cost-aware serving |
Two architecture sketches to consider (textual placeholders you can convert to diagrams):
Explore a reference architecture PDF — downloadable diagrams and templates that map schedulers, registries, telemetry channels, and policy hooks for hybrid deployments.
The Role of Artificial Intelligence in Decentralized Environments
Distributed platforms divide work so nodes handle parts of a request near the source. That approach reduces perceived latency and limits raw data movement while still enabling shared learning and collective improvement across participants.
How AI Performs Tasks:
Learning From Data, Recognizing Patterns, And Making Decisions
Artificial Intelligence uses algorithms trained on data to learn patterns and make predictions or classifications. Models built with machine learning and deep learning techniques run across many machines, so tasks can be split and executed where they are most efficient.
In a decentralized setup, a single user request may traverse nodes, a policy router evaluates identity and consent, a local node handles latency-sensitive subtasks, and remote nodes perform heavier retrieval or aggregation. Policy and routing determine which node performs each subtask based on latency, cost, and data governance.
Natural Language Processing And Human Language Interfaces
Natural language processing enables chat, summarization, intent detection, and other language processing features without relying on a single cloud endpoint. Typical pipelines split work into tokenization (breaking text into tokens), retrieval (finding relevant context), tool calling (invoking external services), and response generation (creating text). Splitting these stages across nodes reduces data movement while preserving functionality.
Example: Flow for a chat request (textual): tokenization → local safety filter → retrieval from a nearby vector store → generation on a shared GPU node → post-processing and delivery. (Parenthetical: tokenization = converting text to model-ready tokens; retrieval = fetching context or documents.) For robust operation, identity, rate limits, and safety filters must be consistent across nodes so virtual assistants and chatbots behave predictably for humans.
Computer Vision And Real-World Perception
Computer vision commonly runs at the edge for cameras, industrial inspection, and autonomous devices. Edge inference can detect anomalies or events locally and send only summaries or aggregated features upstream—minimizing data movement and exposure while keeping latency low.
Example: An industrial camera runs a vision model on-site that flags potential equipment failure and transmits only an encrypted alert and a small feature vector for centralized trending analysis.
| Capability | Edge / Local | Shared Network |
|---|---|---|
| Latency | Low | Moderate |
| Data movement | Minimal | Higher |
| Learning updates | Federated | Centralized sync |
| Operational need | Robust routing | Consistent policy |
See a sample decentralization checklist for NLP/vision systems — practical templates for evaluating data flows, privacy controls, and inference placement.
Centralized vs Decentralized AI Systems
Architectural choices single-provider stacks or shared networks shape ownership, privacy risk, cost, and resilience for deployed solutions. Understanding the trade-offs helps leaders choose the right approach for a given use case and compliance environment.
Control And Ownership:
Single-Provider Platforms Vs Shared Networks
Centralized systems concentrate decision-making and operational control with one vendor or cloud provider. That simplifies integrations, reduces early engineering overhead, and can speed time to market.
Decentralized networks distribute authority across participants and machines. That distribution can increase operational complexity but offers stronger control over where data and computers live, and reduces dependency on a single vendor.
Privacy And Compliance:
Reducing Exposure Of Sensitive Data
Keeping raw data near its origin lowers transfer risks and helps meet regional compliance requirements (for example, data residency components of GDPR or sector-specific rules). Approaches such as federated learning and local preprocessing limit the need to pool datasets centrally, which can reduce regulatory friction.
Scalability And Availability:
Distributed Capacity And “Always-On” Resilience
Networks that span many nodes can route around failures, burst capacity across participants during peaks, and offer improved availability for critical services. Centralized providers may offer strong internal resilience, but scaling is typically constrained by the provider’s boundaries and pricing.
Transparency And Accountability:
Auditability, Explainability, And Provenance
Decentralized systems can increase transparency by using verifiable provenance and shared audit trails; centralized systems often rely on proprietary logs and opaque update processes. Shared logs and signed artifacts help with explainability and accountability across organizations.
Fault Tolerance And Reliability:
Minimizing Single Points Of Failure
Decentralization reduces single-point risk but adds coordination overhead operators must plan redundancy, health checks, and failover policies to avoid cascading outages. Centralized systems simplify coordination but concentrate risk in one environment.
| Aspect | Centralized | Decentralized |
|---|---|---|
| Control | A single vendor governs updates and policies | Shared governance with participant incentives |
| Privacy | Requires central data aggregation | Data can stay local; less raw exposure |
| Scalability | Scale inside provider limits | Burst across many machines and networks |
| Transparency | Proprietary logs and opaque updates | Verifiable provenance and shared audit trails |
| Reliability | Optimized within one environment; single failures risk outage | Built-in routing around node failures; needs redundancy planning |
Decision Guide For CTOS: When To Choose Each
Short Examples
Compare Centralized Vs Decentralized TCO — use this cost model tool to estimate amounts of compute, storage, and recurring operational time for each approach.
Key Challenges to Solve Before Mass Adoption
Real-world deployment will not scale without clear rules, shared standards, robust defenses, and reliable quality controls. These challenges determine whether decentralized systems become practical for enterprises and for critical services that must meet strict compliance and uptime requirements.
Governance And Incentives
Decentralized networks must explicitly define who can approve upgrades, change parameters, or trigger rollbacks. Clear decision rights reduce response time during incidents and make accountability auditable.
Interoperability
Standards for identity, permissions, model packaging, telemetry, and data exchange are required so components from different organizations and clouds can coordinate reliably. Existing efforts—ONNX for model formats, OpenID/OAuth for identity, and community projects for federated learning offer starting points, but broader operational specs and telemetry contracts are still needed.
Security And Adversarial Risks
Threats include model theft, weight tampering, supply-chain compromise, and data poisoning that corrupts learning signals. Defenses should include artifact signing, tamper-evident registries, secure enclaves where appropriate, and continuous integrity verification.
Performance And Quality Control
Latency and throughput can suffer when requests hop across many machines and networks; coordination costs grow with scale. Long-term quality requires drift monitoring, consistent evaluation suites, trusted update channels, and clearly defined rollback strategies so model behavior remains predictable over time.
Operational Recommendation: Combine automated controls (signed artifacts, telemetry, gating) with governance contracts (decision rights, incentives, SLAs) so technical processes and organizational processes align.
A concise template you can use to assess readiness across data, learning processes, and model operations.
Real-World and Emerging Use Cases
Practical use cases show where a distributed operating layer delivers measurable benefits—lower latency, improved privacy, and cost-efficient scaling—across industries.
Web3 Marketplaces For Models And Data
Decentralized marketplaces enable buyers to discover, price, and access models, data, and inference services with built-in provenance and usage tracking. This supports rights enforcement and micropayments to contributors, turning models and labelled datasets into tradeable assets.
Benefit: Marketplaces can reduce time-to-procure models and create new revenue streams while preserving traceability for compliance.
Edge Computing
On-device intelligence keeps inference close to users mobile apps, retail kiosks, and industrial controllers reducing latency and limiting raw data movement. Edge deployments often use smaller models or compressed variants of larger models to meet local compute constraints.
Benefit: Lower response times and reduced data transfer costs, which together improve user experience and total cost of ownership (TCO).
Iot Networks
Distributed sensor streams feed machine learning for monitoring and predictive maintenance. Local preprocessing and federated updates let organizations detect anomalies quickly and share only model updates or aggregated signals to central analytics.
Benefit: Faster detection of failures, lower downtime, and reduced amounts of transmitted data—saving bandwidth and protecting sensitive site-level information.
Autonomous Agents
Agents coordinate goal-driven workflows and call external tools (ticketing, booking, operational APIs). In distributed setups, agents can run locally or collaborate across nodes to complete multi-step processes without constant human supervision.
Benefit: Automation of complex business tasks with built-in audit trails and governance controls that span participating systems.
Enterprise And Critical Environments
Analytics, personalization, fraud detection, and support functions can benefit when departments or partners cannot share raw data. In healthcare, manufacturing, and logistics, decentralized OS capabilities—policy routing, provenance, and local inference—help maintain operations during outages and meet regulatory requirements.
Benefit: Improved availability and compliance while enabling cross-organization learning.
| Use Case | Primary Benefit | OS Capability |
|---|---|---|
| Marketplace | Provenance & access; new revenue | Identity, policy, metering |
| Edge / IoT | Low latency, local privacy | Scheduling, routing, model variants |
| Agents / Enterprise | Automated workflows, robust ops | Observability, governance, audit logs |
Example Scenario: A retail chain deploys seed personalization models to stores (edge), fine-tunes locally on regional data, and shares signed model updates to a central registry reducing per-customer latency while preserving customer privacy and lowering cloud inference costs.
Explore Industry-Specific Playbooks — downloadable guides for Healthcare, Manufacturing, and Retail that describe architectures, expected benefits, and solution patterns.
Future Trends And Innovation Potential
Emerging platforms will let teams assemble modular stacks that mix specialized components—retrieval, policy, routing, and tool calling so services evolve without full rewrites. These composable approaches let operators swap pieces (models, connectors, or tooling) by policy, cost, or latency, accelerating innovation while preserving governance.
| Trend | Benefit | Operational need |
|---|---|---|
| Composable stacks | Faster integration of models and tools | Standard interfaces, versioning |
| Federated learning | Reduced data transfer, better privacy | Secure aggregation, policy controls |
| Inference markets | Cost-efficient scaling of processing | Dynamic pricing, scheduling |
| Agentic ecosystems | End-to-end automation | Permissions, observability, containment |
Which Trends To Pilot First
Research continues to drive these technologies forward, but practical adoption decisions should be guided by clear operational needs, measurable benefits, and incremental pilots that reduce risk over time.
Request A 30-Minute Briefing On How To Pilot Composable Stacks And Federated Learning — a short technical session to align strategy, research, and implementation steps.
Ethical Considerations and Long-Term Industry Impact
When compute and data cross organizational boundaries, ethics must be engineered into protocols and operational processes—not treated as an afterthought. Decentralized systems change who writes the rules, how errors propagate, and who bears responsibility when outcomes cause harm.
Responsible Principles For Distributed Networks
Fairness, robustness, accountability, and explainability must be enforced across participants. Practical controls include mandatory bias testing, standardized evaluation suites, security hardening, and clear update and rollback procedures embedded in governance contracts.
Explainability Across Chained Processes
Decisions in decentralized setups often flow through chains of models and tools hosted on different machines and networks, which makes end-to-end interpretation harder. To preserve interpretability, every request should carry provenance metadata and signed traces so auditors can reconstruct the chain of reasoning.
Operational example: A request that triggers a multi-agent workflow must include an auditable trace showing which model produced which intermediate output, which tool was called, and which policy gates were evaluated.
Privacy, Compliance, And Operational Controls
Keeping raw data local helps meet regional rules, but networks still need policy-based access controls, retention rules, and breach response plans. Signed artifacts and verifiable logs support cross-jurisdictional audits and incident investigations.
Bias, Harm Pathways, And Accountability
Patterns learned from skewed datasets can propagate quickly across nodes. Continuous evaluation against shared benchmarks, routine revalidation, and federated evaluation suites reduce systemic harm. Contracts and governance agreements must specify who investigates incidents and how affected users are compensated or remediated.
If a federated update introduces a bias that affects outcomes for a protected group, signed provenance and evaluation logs enable rapid root-cause analysis, identification of the contributing node, and a coordinated rollback per the governance playbook.
Long-Term Industry Shifts
Shared compute and open marketplaces could shift market power away from a few hyperscalers and create new ownership and monetization models for models and datasets. That outcome is possible but depends on practical governance, robust incentives, interoperable standards, and measurable reliability not on speculative science fiction narratives.
For builders and policy-makers, the priority is measurable metrics standardized bias scorecards, provenance coverage, mean-time-to-rollback, and cross-node SLA compliance. These metrics make ethical obligations operational and auditable.
| Ethical Area | Decentralized Requirement | Operational Example |
|---|---|---|
| Fairness | Shared bias tests and reporting | Federated evaluation suites run before deployment |
| Explainability | End-to-end provenance and logs | Signed request traces across nodes |
| Privacy | Local data controls and audit trails | Policy-based data routing and retention rules |
| Accountability | Clear responsibility contracts | Incident playbooks with named owners |
A practical workbook with checklists, scorecards, and contractual language you can adapt for governance and compliance reviews.
How Webo 360 Solutions Can Help with AI
Webo 360 Solutions focuses on practical engineering and operational patterns that align with decentralized requirements for artificial intelligence. The intent here is educational to show how a technology partner can help organizations plan resilient, privacy-aware AI systems that avoid unnecessary vendor lock-in and support federated, edge-first, or hybrid deployments.

Key ways a neutral technology partner supports decentralized AI systems:
-
✔Architecture And Infrastructure Planning — Inventory existing computers (edge devices, on-prem servers, cloud, GPU pools), design orchestration and scheduler patterns, and recommend telemetry hooks to balance latency, cost, and resilience.
-
✔Data Strategy And Governance — Define access control and consent policies, provenance tracking, and privacy-preserving pipelines (federated learning, secure aggregation, encryption) so sensitive records remain local while contributing to collective learning.
-
✔Model Lifecycle And Operations — Establish model registries, artifact signing, versioning, evaluation suites, rollout/rollback procedures, and trusted update channels to reduce supply-chain risk and preserve auditability.
-
✔Interoperability And Standards — Map vendor APIs, recommend model packaging formats and identity federation patterns, and define telemetry contracts so disparate components interoperate reliably across networks.
-
✔Security And Compliance — Advise on enclave use, key management, tamper-evident logs, incident playbooks, and regional compliance controls so systems meet regulatory expectations while defending against adversarial threats.
Emphasize objective criteria total cost of ownership (TCO), privacy posture, latency and availability targets, auditability, and operational complexity so teams can compare solutions and vendors on a neutral basis.
Practical Deliverables And Timelines
Readiness Checklist
Next Steps For Assessment
Use this checklist as a practical tool to evaluate your organization’s readiness for decentralized AI systems. It helps teams identify gaps in infrastructure, data management, model operations, and governance so you can plan improvements before scaling deployments.
Conclusion
Decentralized operating systems coordinate many hosts so models, data, and policies behave like one managed platform. They let organizations pool compute resources while preserving local control, verifiable provenance, and privacy-aware data handling for artificial intelligence workloads.
Compared with centralized setups, control and ownership are shared across participants. That distribution can improve resilience and reduce the concentration of power, but it also increases coordination needs. Strong identity, policy enforcement, signed provenance, and disciplined lifecycle management matter as much as raw model performance when systems span multiple organizations and machines.
Practical gains include reduced raw data movement, edge-first deployments for low-latency experiences, and flexible training and inference patterns that let teams scale, compute and adapt over time. These patterns make it possible to balance cost, performance, and regulatory constraints in real-world deployments.
Readiness depends on governance, interoperability, security hardening, performance tuning, and consistent evaluation across participants. Investing in these processes up front reduces operational risk and helps ensure the learning and models you deploy remain trustworthy and auditable.
Next Steps For Technical And Business Leaders
Looking ahead, composable stacks, shared inference markets, and agent-driven automation can extend what organizations do with distributed systems. Lasting progress depends on standards, measurable reliability, and responsible oversight so humans can trust outcomes from distributed models and tools.
Decentralized artificial intelligence systems let organizations balance data locality, resilience, and cost by coordinating models and compute across many nodes while requiring strong governance and interoperability.
Download the decentralized readiness checklist and pilot resources — or Schedule A Short Consultation to review a tailored roadmap for your organization.
FAQ
What is a decentralized AI operating system?
Why do decentralized systems matter now?
How do decentralized AI operating systems differ from traditional centralized systems?
Where does decentralization occur across the model lifecycle?
What are the core architectural building blocks?
How does the data layer protect privacy and provenance?
What role do agents and autonomous workflows play?
What security risks should organizations prepare for?
How is performance affected by decentralization?
What interoperability standards are needed?
What governance and accountability mechanisms are recommended?
What real-world use cases are emerging?
How can enterprises adopt decentralized AI operating systems?
What ethical issues arise with decentralization?
What future trends will shape decentralized AI OS development?
Schedule A Short Consultation
to review adoption options tailored to your organization.